Audio localisation for robots - Adaptive filter model of the cerebellum with multiple models for sound source localisation - Mark Baxendale
We run monthly journal club (currently via Zoom) discussing relevant papers in machine learning with applications in astronomy. Here we provide links to the papers and any additional slides a speaker has made. When it becomes safe to return to the office, we anticipate these sessions will be held at the SKA HQ at Jodrell Bank.

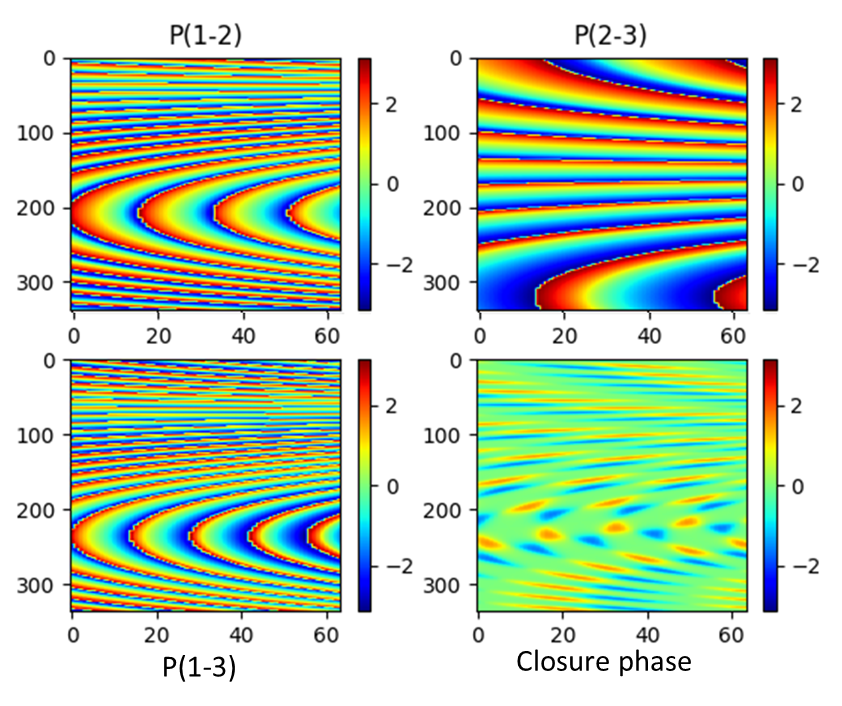
Modern interferometric imaging frequently uses self-calibration to reduce errors from instrumental and propagation effects when synthesising images from measured visibilities. However, the initial image and calibration assumptions used can greatly affect the image produced. A method to image the data using only closure phases and closure amplitudes was suggested by Chael et al. https://arxiv.org/pdf/1803.07088.pdf, which used a regularized maximum likelihood algorithm. We will present our improvements to Chael’s approach by using the pix2pix algorithm developed by Isola et al. https://arxiv.org/pdf/1611.07004.pdf to predict source structures directly from a plot of closure phase values. As the bulk of the work was performed by the model, this only requires a fraction of the computational power needed by Chael’s method. In this talk we will cover the various architectures used in training, how we simulated large quantities of training data, and some of the key results that were obtained.

We present a novel machine learning technique that can be used for generating postage stamp images of synthetic Faranoff Riley Class 1 and Class 2 radio sources. Such a method will be useful in the simulations of future surveys like those being developed by the SKA as it can generate a large amount of unobserved sources. We will introduce the basic concepts used in generative machine learning with a focus on variational auto-encoders (VAE) which is our chosen methodology and will show how this can be applied to radio astronomy for the generation of FRIs and FRIIs.

Approaching a ML project can seem daunting, especially if you haven't seen a project through the full process before. In this talk, I present an overview of what a workflow for a ML project might look like. Each step is explained along side an astronomy-centric example project to help ground each step in practical application, which astronomers can relate to.
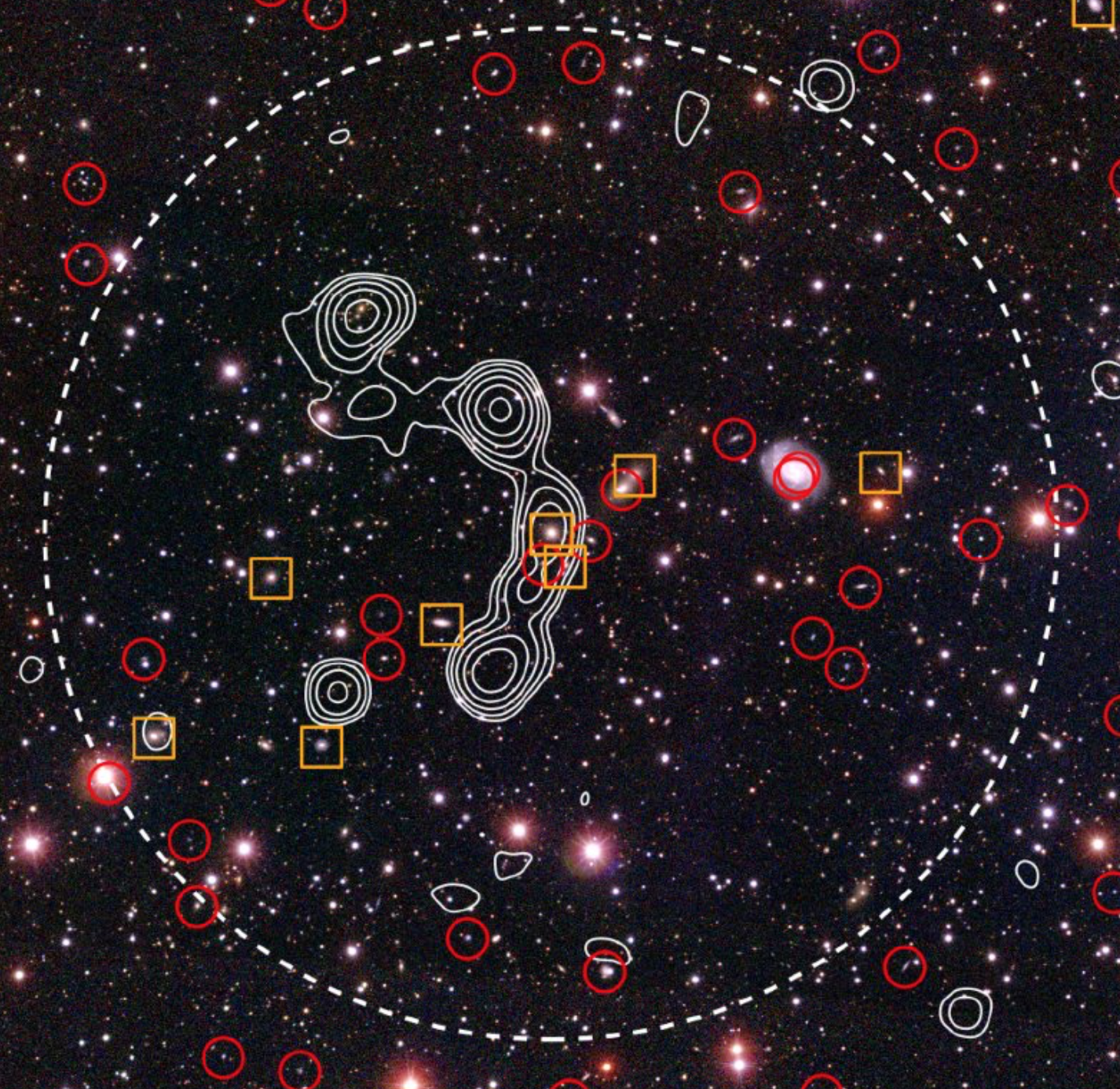
In this talk I will recap the Giant Radio Galaxies searching pipelines people have adopted, and introduce how people have changed their ways of finding these sources, from doing visual inspection by experts, citizen scientists, to recent semi-automated algorithm development. I will also discuss what are the factors necessary when building a training dataset for training GRG-non GRG deep learing classifier.

I will introduce and discuss the advantages of neighbour-graph models for dimension reduction, going over a recent paper that implements a parametric version of an algorithm called UMAP. Their work allows a neighbour-graph loss function to be used with a deep neural network to learn a mapping from a high to a low dimensional space. This means the UMAP loss function can be used in combination with auto-encoder or classifier loss functions, for data generation or semi-supervised learning. The UMAP loss function is particularly suited to regularising a deep neural network using sampled batches of data, allowing real-time signal processing on big datasets (transients, pulsars, RFI).

An end-to-end-trainable attention module for convolutional neural network (CNN) architectures built for image classification.

Formed when the light from a background galaxy is deflected by the mass of a foreground galaxy, strong gravitational lenses are exotic cosmic objects, manifesting as dramatic arcs and rings in space. Since the amount of deflection is independent of the type of matter, strong lenses can be used to investigate the distribution of dark matter, allowing us to map and measure the dark Universe. Within the next decade several new sky surveys will yield hundreds of thousands of new lenses, creating a statistically robust sample for the first time. Exploiting the scientific potential of these rare objects now depends on finding them within huge datasets. Of high importance are the abilities of a finder both to outperform a human and to reject false positives due to intrinsic structure in galaxies. I will present the support vector machine technique we have developed which does exactly this - https://arxiv.org/abs/1705.08949. I will also present the results of the application of our finder to the Strong Gravitational Lens Challenge, and to the search for lenses in real-life observations, where we have successfully found over a hundred new strong lens candidates - https://arxiv.org/abs/1802.03609.
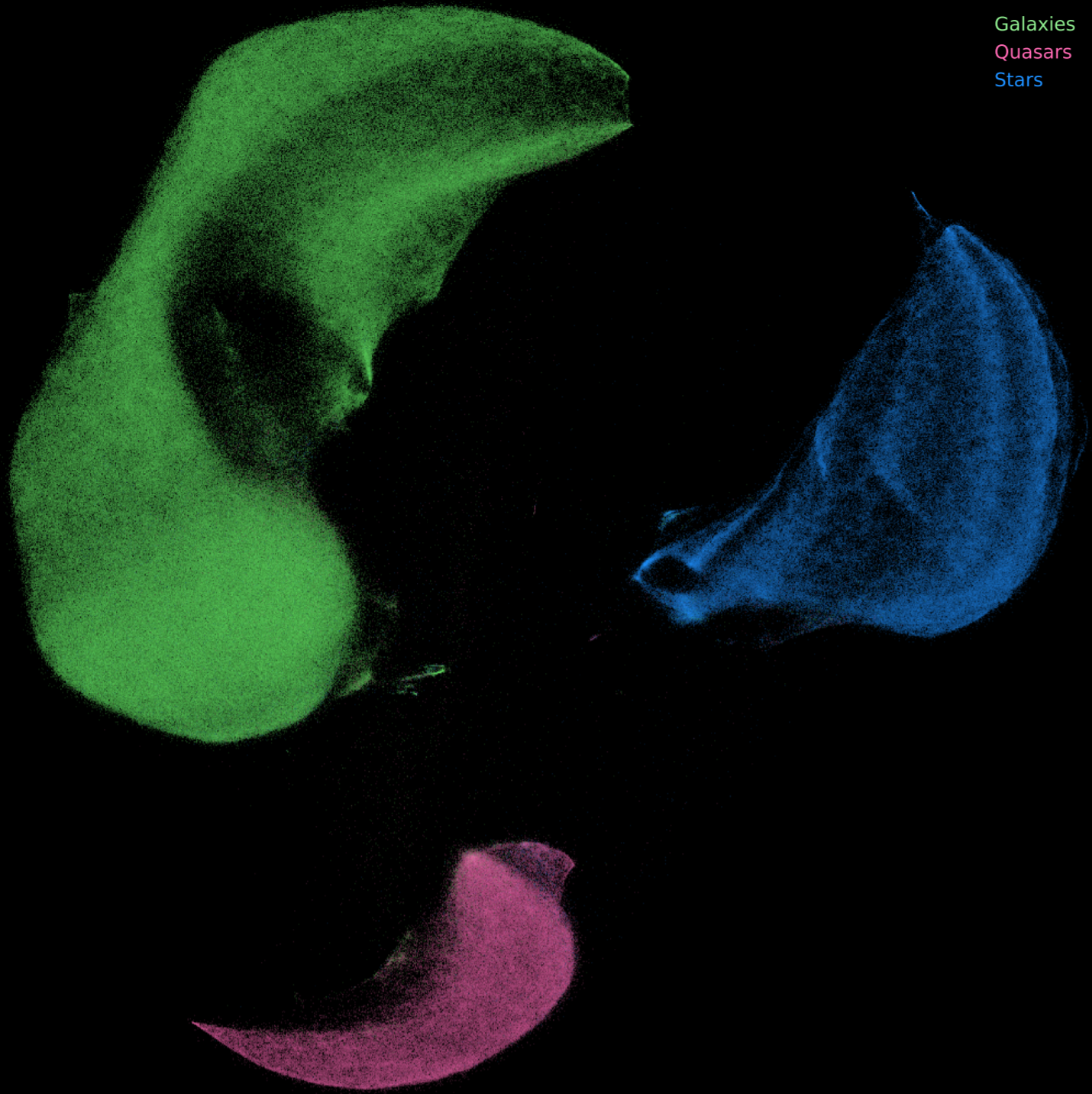
I will discuss my recent paper titled: Identifying galaxies, quasars, and stars with machine learning: A new catalogue of classifications for 111 million SDSS sources without spectra: https://arxiv.org/abs/1909.10963. Here I focus on using a Random Forest to classify sources based on photometry, and also use dimension reduction with UMAP to visualise the classifications. I’ll also briefly discuss a paper that investigates obtaining photometric redshifts for sources found in radio surveys: Quasar photometric redshifts from SDSS, WISE and GALEX colours - https://arxiv.org/abs/2001.06514v1.
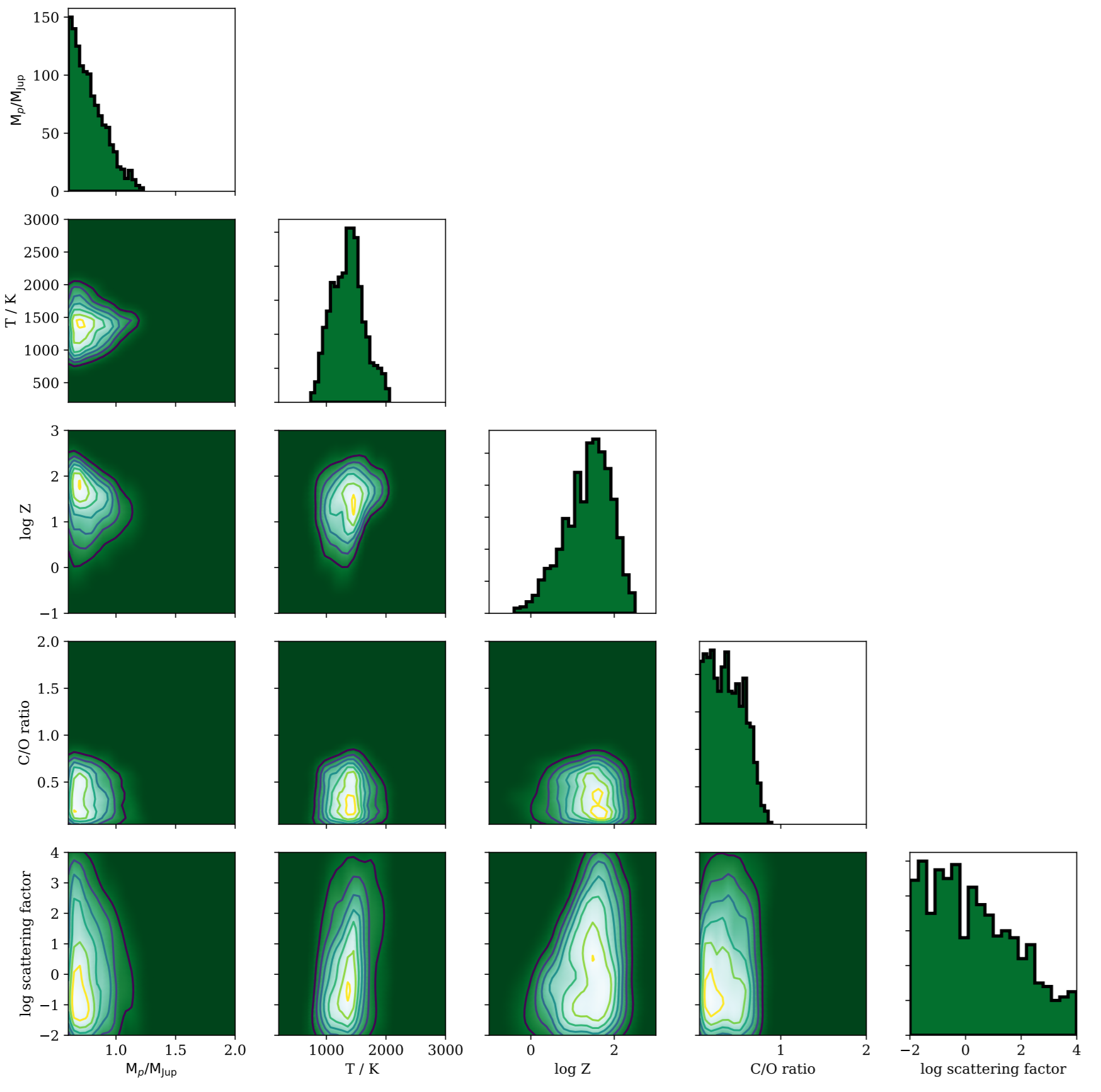
Optimizing exoplanet atmosphere retrieval using unsupervised machine-learning classification.
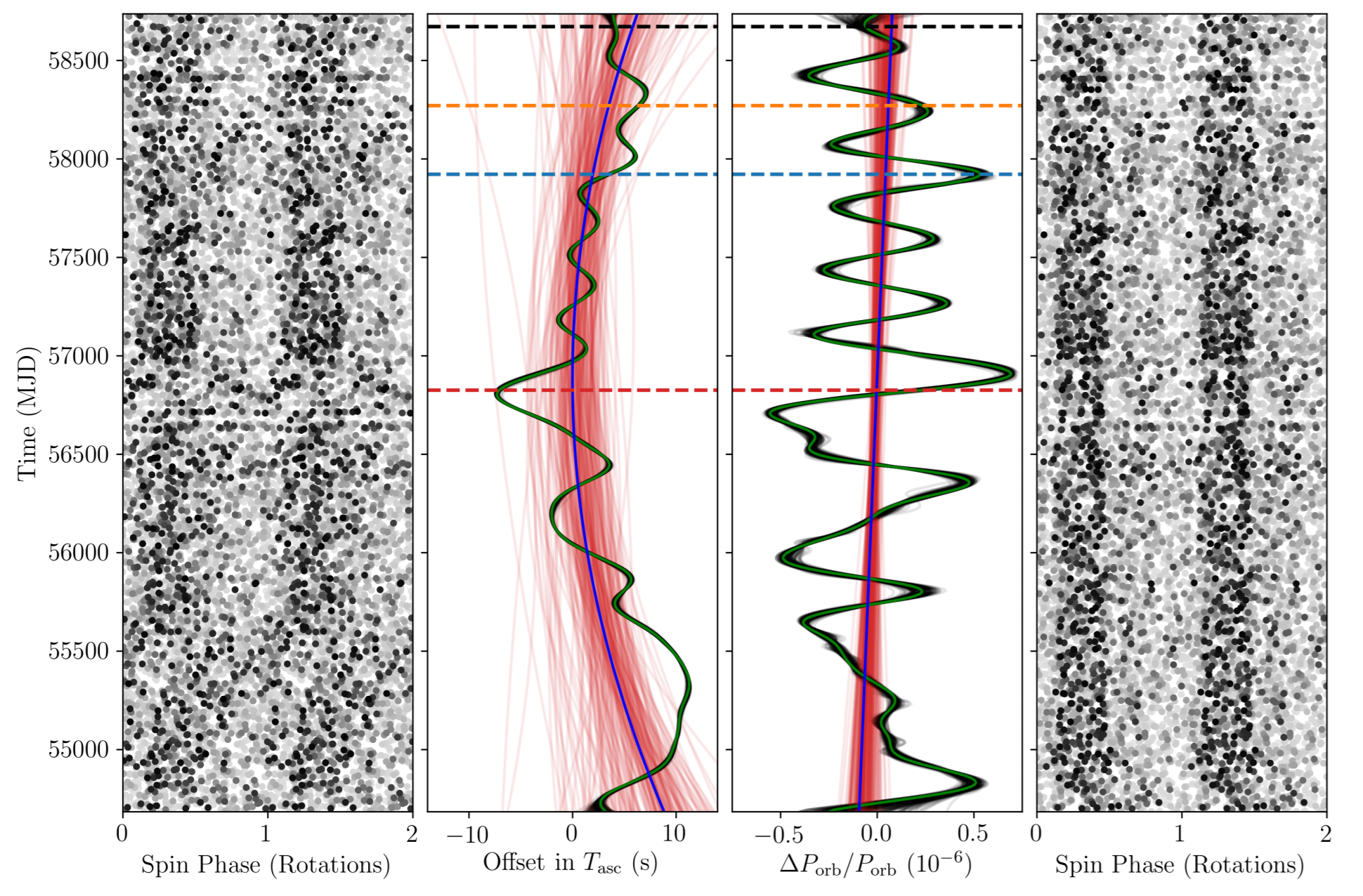
Timing Gamma-ray Pulsars using Gaussian Processes.